



Forschung
Lehrstuhl für KI in der Medizin
Unsere Forschung fokussiert sich auf die Entwicklung von neuen Algorithmen und Methoden für Anwendungen in der Medizin.
Dabei ist es unser Ziel, Techniken der künstlichen Intelligenz (KI) und des maschinellen Lernens (ML) für die Analyse und Interpretation hochdimensionaler, biomedizinischer Daten zu entwickeln. Anwendungsschwerpunkte sind:
- KI zur Prävention und Diagnose von Krankheiten
- KI zur personalisierte Interventionen und Therapien
- Identifizierung neuer Biomarker und Interventionsziele für Krankheiten
- sichere, robuste und interpretierbare KI-Ansätze
- KI-Ansätze zur Wahrung der Privatsphäre
Unser besonderes Interesse gilt der Anwendung von biomedizinischer Bildgebung und KI-Methoden zum besseren Verständnis der Gehirnentwicklung (in-utero und ex-utero), zur Verbesserung der Diagnose und Stratifizierung von Patient*innen mit Demenz, Schlaganfall und traumatischen Hirnverletzungen sowie zur umfassenden Diagnose und Behandlung von Herz-Kreislauf-Erkrankungen und Krebs.
Die folgenden Arbeitsgruppen sind im Lehrstuhl angesiedelt:
- KI für biomedizinische Bildanalyse und Interpretation
- Inverse Probleme in der biomedizinischen Bildgebung
- Privatsphärenwahrende und vertrauenswürdige KI in der Medizin
KI für biomedizinische Bildanalyse und Interpretation
Medizinische Bildgebung erlaubt es, ohne invasiven chirurgischen Eingriff in das Innere des menschlichen Körpers zu blicken. Zur medizinischen Bildgebung gehören Verfahren wie Computertomografie (CT), Magnetresonanztomografie (MRT) und Ultraschall (US). Ärzt*innen können anhand der gewonnenen Aufnahmen untersuchen, Krankheiten diagnostizieren und über Behandlungen entscheiden.
Unsere Gruppe entwickelt Techniken und Algorithmen, die klinisch nützliche Informationen aus medizinischen Bildern extrahieren und Ärzt*innen so unterstützen können. Die Algorithmen sind in der Lage, automatisch Krankheiten zu diagnostizieren, Krankheitsverläufe vorherzusagen, relevante anatomische Strukturen zu kennzeichnen oder Bilder zu vergleichen, die zu unterschiedlichen Zeitpunkten oder mit verschiedenen Bildgebungsgeräten aufgenommen wurden.
Besondere Herausforderungen im klinischen AnwendungsbereichDie zum Trainieren unserer Methoden erforderlichen Datensätze sind klein und benötigte Annotationen aufwändig zu beschaffen. Häufig müssen bei der Auswertung der Bilder auch weitere medizinische Informationen berücksichtigt werden, wie zum Beispiel Arztnotizen, Laborbefunde oder genomische Informationen. Darüber hinaus muss beachtet werden, wie die Algorithmen in den klinischen Arbeitsablauf passen, damit die entwickelten Methoden schlussendlich erfolgreich im Krankenhaus eingesetzt werden können.
Weitere Informationen
Wir sind immer auf der Suche nach talentierten Gruppenmitgliedern, die im Rahmen ihres Forschungsprojektes oder ihrer Abschlussarbeit mit uns zusammenarbeiten möchten. Besonders interessiert sind wir an Mitarbeiter*innen mit Erfahrung in den folgenden Bereichen:
- künstliche Intelligenz und maschinelles Lernen
- Deep Learning
- biomedizinische Bildgebung
- Computer Vision
Sind Sie an einer Zusammenarbeit mit uns interessiert? Wir freuen uns auf Ihre E-Mail!
- Imperial College London
- Helmholtz Zentrum München
- Abteilungen für Radiologie und Neuroradiologie, TUM
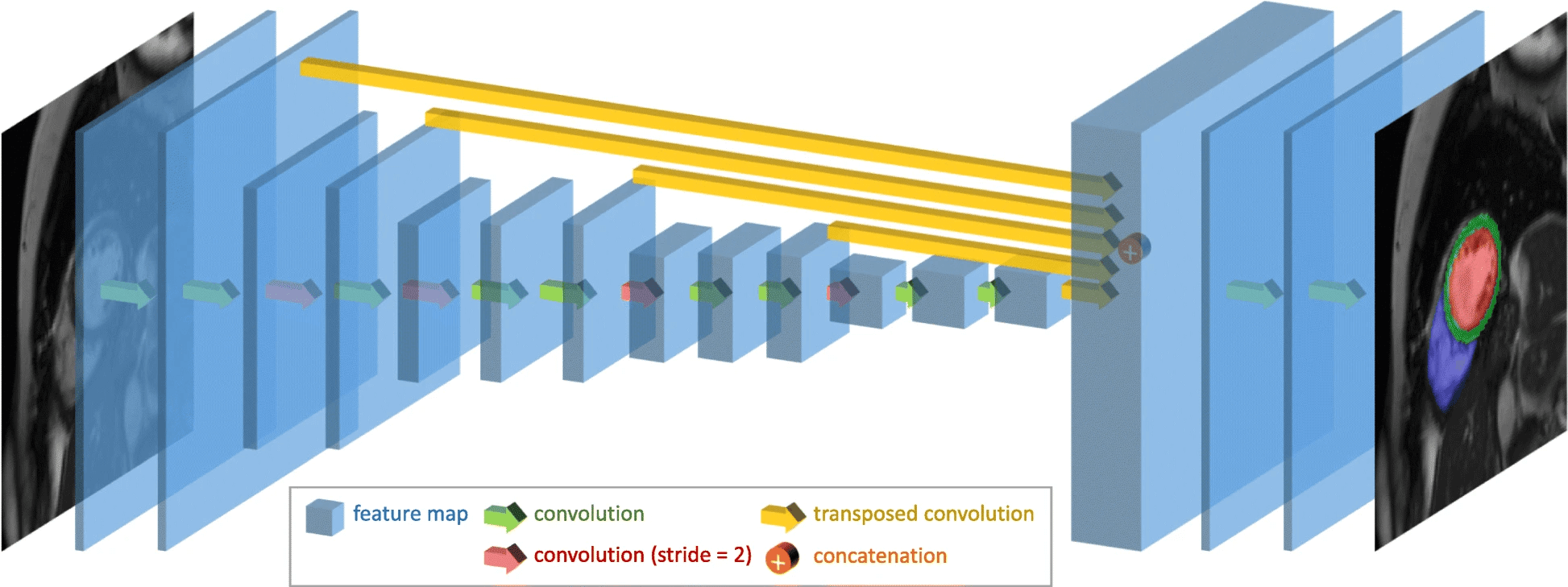
Abbildung 1:
Einer der Schwerpunkte unserer Forschung ist der Einsatz von Deep Learning Ansätzen, hier z.B. Convolutional Neural Networks (CNN), zur Segmentierung biomedizinischer Bilder.
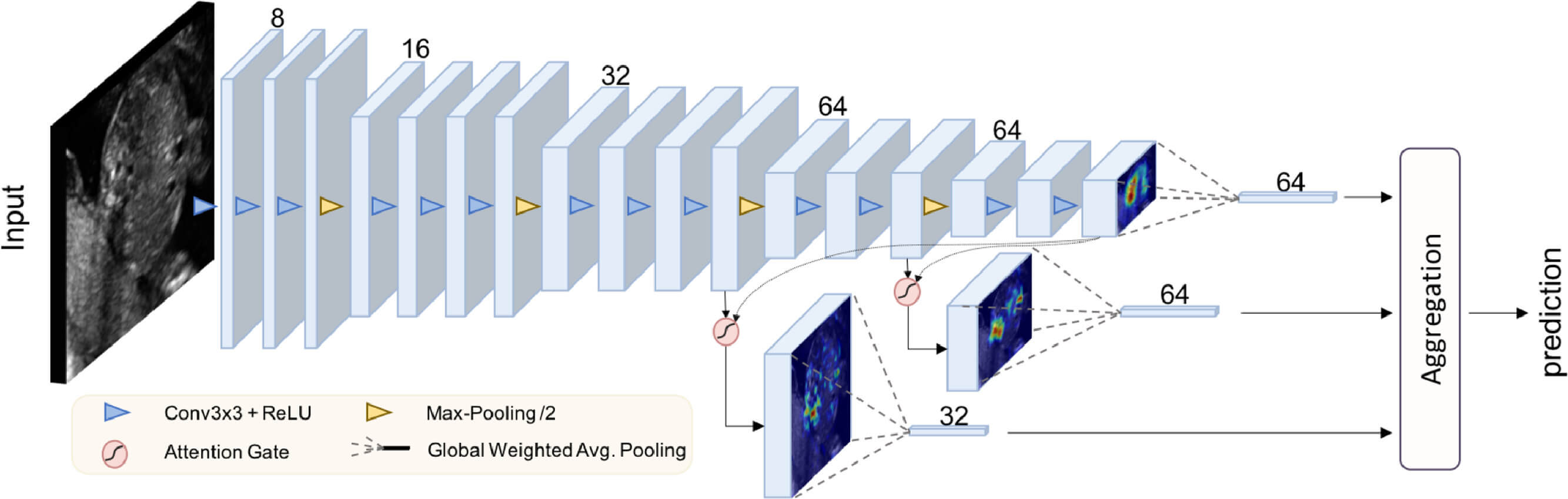
Abbildung 2:
Beim Einsatz von KI zur Analyse und Interpretation von biomedizinischen Bildern ist es oft wichtig, erklärbare KI-Methoden zu verwenden, hier z.B. durch Attention-Mechanismen.
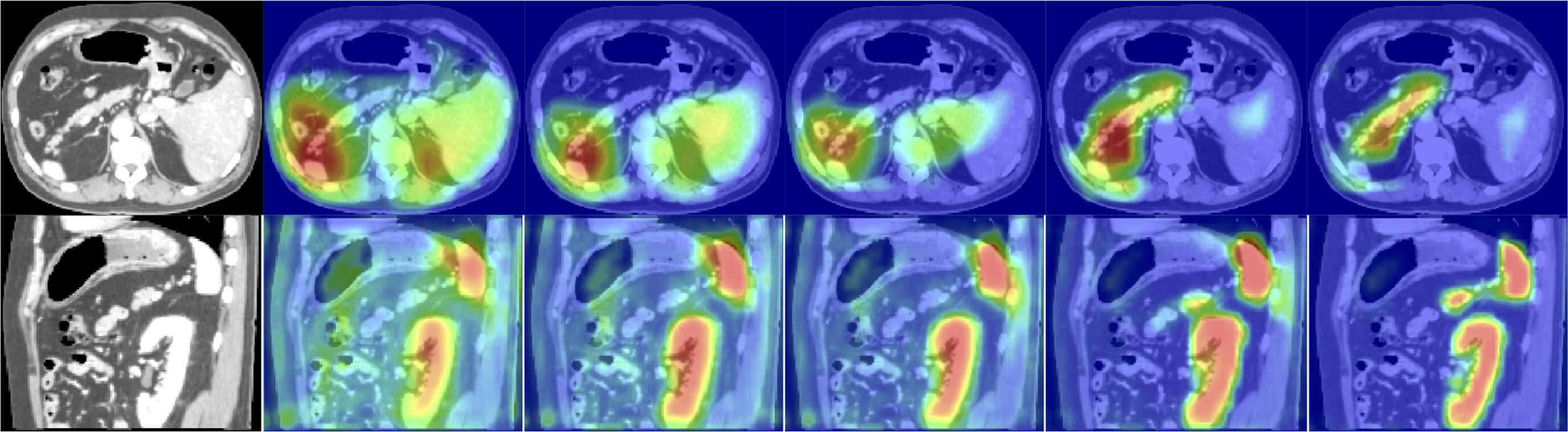
Abbildung 3:
Attention-Mechanismen erlauben es, die Bildregionen zu identifizieren, die wichtige anatomische Informationen enthalten, hier z.B. in CT Bildern des Abdomens.
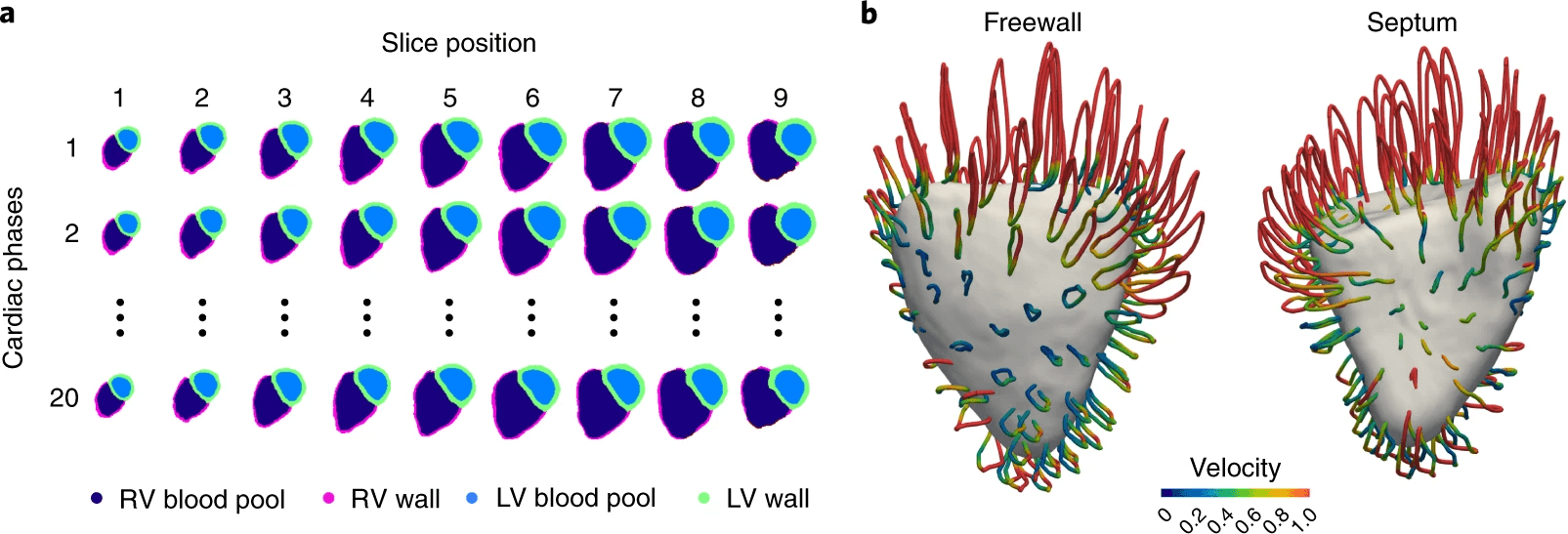
Abbildung 4:
Zur Diagnose von Krankheiten müssen oft nicht nur anatomische Informationen aus Bildern extrahiert werden, sondern auch funktionelle Informationen, hier z.B. die Bewegung des Herzens.
Gruppenleitung











Julian McGinnis
MSc. Electrical Engineering and Information Technology

Inverse Probleme in der biomedizinischen Bildgebung
Unsere Gruppe beschäftigt sich mit inversen Problemen in der biomedizinischen Bildgebung und ihrer Lösung mithilfe von künstlicher Intelligenz und maschinellem Lernen.
Deep Learning für inverse Probleme
Die Entwicklung von Algorithmen zur Lösung inverser Probleme, die bei Sensor- und Bildgebungssystemen auftreten, hat eine lange Tradition. Beispiele hierfür sind Compressed-Sensing-Ansätze, z. B. für die medizinische und computergestützte Bildgebung. Bis vor Kurzem basierten die meisten Algorithmen zur Lösung inverser Probleme auf statischen oder physikalischen Signalmodellen, wie zum Beispiel Wavelets oder spärliche Darstellungen. Unsere Forschung konzentriert sich auf leistungsfähige Ansätze auf Basis von Deep Learning, bei dem die verschiedenen Elemente zur Lösung inverser Probleme erlernt werden, darunter: i) Signaldarstellungen, ii) die Parameter iterativer Algorithmen, iii) regularisierte und iv) ganze inverse Funktionen.
KI-basierte Bildrekonstruktion
Deep Learning-basierte Ansätze zur Rekonstruktion von Magnetresonanztomografie (MRT) oder Computertomografie (CT) liefern leistungsstarke KI-Modelle, die es erlauben, MRT-Bilder zu generieren, auch wenn der Signalraum nur unvollständig abgetastet wurde, sowie hochqualitative CT-Bilder aus sog. „low-dose“-Röntgenaufnahmen zu errechnen. Forschungsschwerpunkt ist hierbei, wie diese Deep Learning-basierten Ansätze für klinische Anwendungen (z. B. die kardiovaskuläre Bildgebung) optimiert und diese mit Bildanalysemethoden kombiniert werden können.
Weitere Informationen
Wir sind immer auf der Suche nach talentierten Gruppenmitgliedern, die im Rahmen ihres Forschungsprojektes oder ihrer Abschlussarbeit mit uns zusammenarbeiten möchten. Besonders interessiert sind wir an Mitarbeiter*innen mit Erfahrung in den folgenden Bereichen:
- künstliche Intelligenz und maschinelles Lernen
- Deep Learning
- biomedizinische Bildgebung
- Computer Vision
Sind Sie an einer Zusammenarbeit mit uns interessiert? Wir freuen uns auf Ihre E-Mail!
- Imperial College London
- King‘s College London
- Universität Tübingen
- Helmholtz Zentrum München
- Abteilungen für Radiologie und Neuroradiologie, TUM
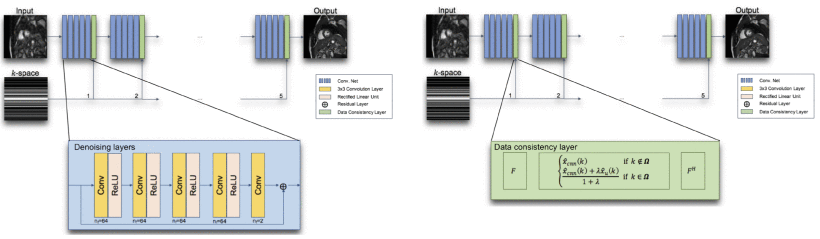
Abbildung 1:
Convolutional Neural Networks (CNN) zur Rekonstruktion von kardiovaskulären MRT Bildern
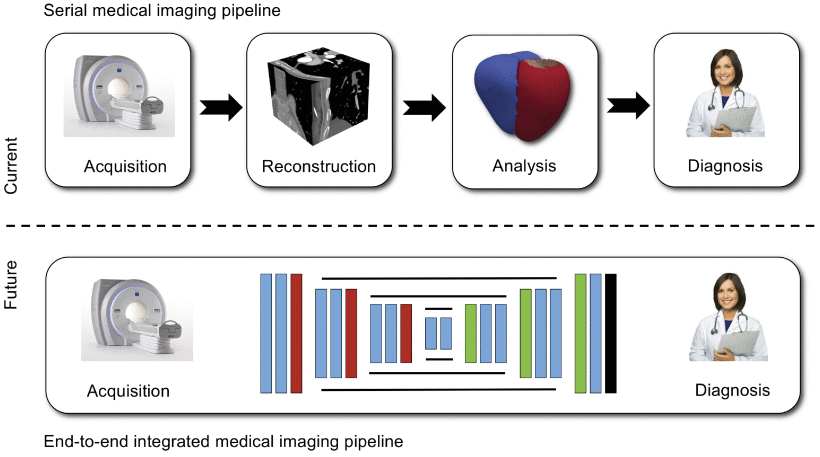
Abbildung 2:
Traditionelle Bildgebungs-Pipeline vs. KI-gestütze Bildgebungs-Pipeline
Gruppenleitung




Privatsphärenwahrende und vertrauenswürdige KI in der Medizin
Unsere Gruppe entwickelt die nächste Generation privatsphärewahrender und vertrauenswürdiger KI-Algorithmen für medizinische Anwendungen.
Künstliche Intelligenz und Schutz der Privatsphäre
KI in der Medizin verlangt große, vielfältige und repräsentative Datensätze, um faire, verallgemeinerbare und zuverlässige Modelle zu trainieren. Solche Datensätze enthalten jedoch sensible persönliche Informationen. Die Privatsphäre schützendes maschinelles Lernen überbrückt die Kluft zwischen Datennutzung und Datenschutz, indem es das Training von KI-Modellen auf privaten Daten ermöglicht und gleichzeitig formale Datenschutzgarantien bietet.
Unsere Gruppe konzentriert sich auf Anwendungen von Differential Privacy auf maschinelles Lernen und Deep Learning, sowohl auf unstrukturierte Datensätze wie Bilder als auch auf strukturierte Daten wie Tabellen- und Graphdatenbanken. Darüber hinaus entwickeln wir Techniken zur Abschwächung von Kompromissen zwischen Privatsphäre und Modellnutzen sowie zwischen Privatsphäre und Rechenleistung. Ebenso untersuchen wir Angriffe auf Protokolle des kollaborativen maschinellen Lernens (z. B. föderiertes Lernen) und entwickeln entsprechende Verteidigungsmaßnahmen.
Künstliche Intelligenz und Vertrauensaufbau
Der Aufbau von Vertrauen in die KI erfordert Techniken zur Quantifizierung der Unsicherheit von Modellergebnissen, zur Einbeziehung von Fachwissen und zur optimalen Bewältigung des Trainings auf kleinen Datensätzen. Ein weiterer Schwerpunkt der Arbeit unserer Gruppe ist die Entwicklung probabilistischer Modelle des maschinellen Lernens (Probabilistic machine learning), die der Tendenz konventioneller Modelle entgegenwirken, schlecht kalibrierte Vorhersagen zu treffen. Wir verwenden computergestützte Bayes'sche Techniken, um sowohl statistische als auch Deep Learning-Algorithmen zu trainieren, und wir arbeiten an der Schnittstelle zwischen probabilistischem und die Privatsphäre wahrendem maschinellen Lernen.
Weitere Informationen
Wir sind laufend auf der Suche nach talentierten Gruppenmitgliedern, die im Rahmen ihres Forschungsprojektes oder ihrer Abschlussarbeit mit uns zusammenarbeiten möchten. Besonders interessiert sind wir an Mitarbeiter*innen mit einem Hintergrund in folgenden Bereichen:
- angewandtes oder theoretisches maschinelles Lernen/Deep Learning
- Kryptografie
- Signalverarbeitung und Informationstheorie
- reine und angewandte Mathematik/theoretische Informatik
- wissenschaftliches/numerisches Rechnen und probabilistische Programmierung
Sind Sie an einer Zusammenarbeit mit uns interessiert? Wir freuen uns auf Ihre E-Mail!
-
Imperial College London
-
Helmholtz Zentrum München
-
Institut für Radiologie, TUM
-
Lehrstuhl für Mathematik, LMU
-
OpenMined













